By Sergey Tselovalnikov on 29 June 2017
Fantastic DSLs and where to find them
Hi!
Kotlin is a very rich language. Unlike many other languages, it allows developers to create another language inside it. For example, to mimic HTML syntax or to build a completely typed SQL query. But Kotlin’s power isn’t limited to simple DSLs. With some Kotlin-fu, it’s possible to write a DSL that allows manipulating untyped data structures in a typed manner. In this article, we’ll go through different ways to define DSL in Kotlin, from very simple to fantastically powerful.

Peter the Great at one time even considered moving the capital of Russia to Kotlin Island, proof of the sovereign’s great affinity with water. This utopian idea failed, but many of the fantasies of this baroque autocrat still managed to become implemented.
Some parts of this article might be hard to understand without knowledge of Kotlin syntax. I tried to explain every feature I showed, but the general ability to speak Kotlin is strongly suggested.
So, let’s begin the journey.
What is s DSL
Domain-specific language (noun): a computer programming language of limited expressiveness focused on a particular domain
— Martin Fowler Domain-Specific Languages
Here though, I prefer to give DSLs a slightly different definition which reflects what is written in the article
a language (or a set of abstractions) that’s built to deal with a specific domain
The main difference is that a DSL might not only be a separate language but also a subset of a language which is used to work on a specific domain. This kind of DSL can even be built in Java with some fluent API, but very often it’s indistinguishable from a plain good code. To contrast in Kotlin, many remarkable features might make an internal DSL look different.
Calling convention
The first feature actively used by DSLs in Kotlin is a special calling convention. If the last parameter of a method is a function, and you’re passing a lambda expression there, you can specify it outside of parentheses.
For example, if one wants to create a function dotimes that takes a
number n, a function f and applies it, the easiest way to do that is
good old dotimes
fun dotimes(n: Int, f: () -> Unit) {
for (i in 0..n-1) {
f()
}
}
The dotimes can be called in this way
dotimes(5, {
println("Hello, Kotlin!")
})
Or, using the lambda parameter convention and placing lambda function outside parentheses.
dotimes(5) {
println("Hello, Kotlin!")
}
Moreover, the parentheses can be omitted completely if a lambda is the
only parameter of a function. E.g. do5times function that only takes a
lambda as a parameter can be defined and called as
fun do5times(f: () -> Unit) = dotimes(5, f)
do5times {
println("Hello, Kotlin!")
}
But despite being important, that calling convention is just a tiny contribution to DSLs when compared to extension functions.
Extension functions
Extension functions simply allow you to extend the functionality of a class from the outside.
Simple extension function
fun String.removeSpaces(): String {
return this.filter({ c -> c != ' ' })
}
print("Hi ! , ext".removeSpaces()) // "Hi!,ext"
Here, the removeSpace function is defined on the class String which
enables an ability to call removeSpaces on any String instance.
Unsurprisingly, it removes all the spaces from it. Inside the functions,
this refers to the instance of a receiver class and can be omitted
like you do when you’re writing a member function. That might sound
complicated if you have never heard about extension functions before,
but looking at the result of the compilation might make it much easier
to understand.
Decompiled java code
public static String removeSpaces(String $receiver) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < $receiver.length(); i++) {
char c = $receiver.charAt(i);
if (c != ' ') {
sb.append(c);
}
}
return sb.toString();
}
Extension functions are not some kind of magic. It’s not a Groovy-like monkey patching, they get compiled to simple static functions. But that example shows us a very important caveat - extension functions are resolved statically because there is no dispatch mechanism for static methods
Even though this snippet is very simple, it can raise another question -
"where did the StringBuilder came from?". An close look at the first
snippet through Java glasses gives the answer - there is no function
called filter defined in the class String. filter is also an
extension function defined in the Kotlin standard library.
filter function from kotlin stdlib
public inline fun String.filter(predicate: (Char) -> Boolean): String {
val destination = StringBuilder()
for (index in 0..length - 1) {
val element = get(index)
if (predicate(element))
destination.append(element)
}
return destination.toString()
}
Kotlin defines a lot of extension functions for Java classes in the
standard library. That’s why Kotlin is so convenient to use. One might
notice that the function has an inline modifier on it which explains
why decompiled removeSpaces has a StringBuilder inside and not a
call to filter.
Many newcomers to Kotlin use the inline modifier everywhere under the
impression that inlining can improve performance. It can, but in many
cases, inline functions don’t improve performance at all, they even can
make it worse. There is an inspection for that in IntelliJ IDEA.

There are also some other uses for inline which can be found in
docs.
Extension function on generic type
The Kotlin compiler is smart enough to allow for the definition of
extension functions on a certain generic type. In this example,
toIntArray function can be called only on a collection that contains
integers. This makes extension functions truly unique, there is no way
(without subclassing) to define a method for Collection class that can
be called only on an Int collection.
fun Collection<Int>.toIntArray(): IntArray {
val result = IntArray(size)
var index = 0
for (element in this)
result[index++] = element
return result
}
listOf(1, 2, 3).toIntArray() // works
listOf("1", "2", "3").toIntArray() // type error
If Kotlin has become your native language, you might be wondering now, why I’m talking about these simple features in an article about DSLs. The thing is, the majority of Kotlin DSLs are based on the expressiveness of the two features mentioned above.
First simple DSL
Given the aforementioned features, it’s very easy to write a first very simple DSL.
Let’s say we need to write an event-based droid fighting platform so that users can provide their own strategies and register them on the platform. For each event the user is interested in, they must provide a callback with the droid’s behaviour. A droid has an interface with a few methods for defeating other droids. Or, humans if you will.
the droid
interface Droid {
val peopleAround: Boolean
val gun: Gun
fun fire(gun: Gun)
fun moveLeft()
fun moveRight()
}
This sounds like an ideal case for DSL and now we need to define a public API which the clients will be happy to use. To provide the droid’s behaviour we’ll write a public function.
API
private val droid: Droid = getDroid() // inaccessible from the public API
public fun on(cmd: String, f: Droid.() -> Unit) {
// ...
droid.f()
// ...
}
The type of the argument f might look weird, but it’s just the type of
0-arity extension function on the type Droid. And finally, the APIs
consumers can register events in the platform.
strategy example
on("back") {
moveLeft()
if (peopleAround) {
fire(gun)
}
}
Here, the anonymous extension function is a second parameter and
therefore can be written outside parentheses. this in the function has
a type Droid and therefore moveLeft() as well as other functions and
properties can be called by themselves without providing an explicit
receiver type..
The strategy looks very natural, it clearly says that if our droid
receives a back command, it should move left and try to shoot some
folks around him. The next snippet shows to what it can be compiled to
in order to make it even clearer for those who don’t speak kotlin well
yet.
decompiled java call
on("back", new Function1<Droid, Unit>() {
public Unit invoke(Droid droid) {
droid.moveLeft();
if (droid.getPeopleAround()) {
droid.fire(droid.getGun());
}
return Unit.INSTANCE;
}
});
HTML builders
Building DSLs using extension functions isn’t limited to simple droid fighting strategies. For example, it allows us to build a completely typed HTML syntax; HTML builders are even mentioned in the official documentation.
html builders
val list = listOf("Kotlin", "is", "awesome")
val result: HTML =
html {
head {
title { +"HTML DSL in Kotlin" }
}
body {
p {
+"a line about Kotlin"
}
a(href = "jetbrains.com/kotlin") {
+"Kotlin"
}
p {
+"Kotlin is:"
ul {
for (arg in list)
li { +arg }
}
}
}
}
println(result)
And these type-safe builders aren’t a Kotlin invention, on the JVM land they were originated in Groovy. But Groovy is a dynamic language, builders there are not type-safe.
It wouldn’t be completely fair to say that even though it’s what Kotlin’s documentation says, Groovy supports static compilation optionally and there are some ways to compile builders statically as well.
The implementation of a DSL in dynamically typed languages is often very different to statically typed languages. In Kotlin, in order to build a DSL, you need to describe the whole schema of the future language. And given that the result is a deeply nested data structure, the easiest way to convert it to string is to traverse the whole data-structure recursively.
base interface
interface Element {
fun render(builder: StringBuilder, indent: String)
}
The simplest line of text can be represented as
class TextElement(val text: String) : Element {
override fun render(builder: StringBuilder, indent: String) {
builder.append("$indent$text\n")
}
}
The real tag representation is a bit more complex
abstract class Tag(val name: String) : Element {
val children = arrayListOf<Element>()
val attributes = hashMapOf<String, String>()
// open tag
// render attributes
// render children recursively
// close tag
override fun render(builder: StringBuilder, indent: String) {
builder.append("$indent<$name${renderAttributes()}>\n")
for (c in children) {
c.render(builder, indent + " ")
}
builder.append("$indent</$name>\n")
}
private fun renderAttributes() = attributes.map { (k, v) -> " $k=\"$v\"" }.joinToString("")
protected fun <T : Element> initTag(tag: T, init: T.() -> Unit) {
tag.init()
children.add(tag)
}
operator fun String.unaryPlus() {
children.add(TextElement(this))
}
override fun toString(): String {
val builder = StringBuilder()
render(builder, "")
return builder.toString()
}
}
It contains a representation of attributes and a set of children. But
the main part that requires attention is the initTag function which
looks very similar to the function on from the "robot fighting" DSL
definition.
Another interesting part is an extension function unaryPlus defined as
an operator for class String inside the Tag. It allows us to use a
convenient (but let’s be honest not obvious at all) way to insert a line
of text inside code like:
¯\_(ツ)_/¯ unary plus to append a line of text
body {
+"just a random line"
+"another line"
}
And the rest of the DSL is an enumeration of all possible tags.
<head>,<title>,<body>,<a>,<ul>,<li>,<p>
class HTML : Tag("html") {
fun head(init: Head.() -> Unit) = initTag(Head(), init)
fun body(init: Body.() -> Unit) = initTag(Body(), init)
}
class Head : Tag("head") {
fun title(init: Title.() -> Unit) = initTag(Title(), init)
}
class Title : Tag("title")
abstract class BodyTag(name: String) : Tag(name) {
fun p(init: P.() -> Unit) = initTag(P(), init)
fun ul(init: UL.() -> Unit) = initTag(UL(), init)
fun a(href: String, init: A.() -> Unit) {
val a = A()
initTag(a, init)
a.href = href
}
}
class Body : BodyTag("body")
class UL : BodyTag("ul") {
fun li(init: LI.() -> Unit) = initTag(LI(), init)
}
class LI : BodyTag("li")
class P : BodyTag("p")
class A : BodyTag("a") {
var href: String
get() = attributes["href"] ?: ""
set(value) {
attributes["href"] = value
}
}
As you can see, all these classes define a possible hierarchy of calls. This DSL is just a toy DSL, and therefore it covers a very small and limited subset of HTML. It is extremely tedious to write the whole HTML DSL manually. The actual HTML DSL implementation uses a real XSD schema to generate all possible classes for the DSL.
There is always a problem
This could already be awesome, but the example demonstrates a very weird behaviour — nobody stops you from defining tags inside each other multiple times.
the problem
head {
head {
head {
// stil possible to write head because implicit receiver html is available
}
}
title { +"XML encoding with Kotlin" }
}
Prior to Kotlin 1.1, the only solution was to redefine function with deprecation.
class Head : Tag("head") {
@Deprecated(message = "wrong scope", level = DeprecationLevel.ERROR)
fun head(init: Head.() -> Unit) = initTag(Head(), init)
fun title(init: Title.() -> Unit) = initTag(Title(), init)
}

The problem with this approach is that it requires an incredible amount
of boilerplate and a full understanding of all possible combinations. In
1.1,
KEEP-57
introduced an alternative to that approach: the @DslMarker annotation
was introduced which allows us to define a DSL marker and introduces a
set of rules for classes annotated with that marker:
-
an implicit receiver may belong to a DSL if marked with a corresponding DSL marker annotation
-
two implicit receivers of the same DSL are not accessible in the same scope
-
the closest one wins
-
other available receivers are resolved as usual, but if the resulting resolved call binds to such a receiver, it’s a compilation error
So, the HTML DSL can be fixed by introducing a @HtmlTagMarker DSL
marker and annotating Tag with it.
@HtmlTagMarker
abstract class Tag(val name: String) : Element {
// ...
}

DSLs that give us an ability to construct nested data structures such as HTML builders, different configurations, UI builders, etc. is where Kotlin really shines. Kotlin took an awesome idea from Groovy and made it safe and easy to use.
There are a few more examples of DSLs of that kind:
But unsurprisingly, it’s not the only type of DSL that can be implemented in Kotlin…
Fantastic DSL
Not all domains are born the same. Let’s consider a completely different domain. A system which handles transactions containing a payment in some currency and two people - a sender and a receiver.

The transaction structure has to be immutable to make it safer. But sometimes, we might need to create a new transaction with an updated field. For example, the name of the receiver (from) person might need to be changed to let’s say "John". There are a few ways to implement that in Kotlin
Data classes
Let’s start with an idiomatic Kotlin way. The class hierarchy can be concisely represented as
data
data class Transaction(val payment: Payment, val parts: Parts)
data class Payment(val currency: String, val amount: Int)
data class Parts(val from: Person, val to: Person)
data class Person(val id: Int, val name: String)
An instance of the Transaction can easily be created as well
create
val trs = Transaction(
Payment("AUD", 15),
Parts(
Person(0, "Alex"),
Person(1, "Ben")
)
)
But problems start when we need to update this nested data structure. Generally, there two ways to do that. The first option is to completely recreate the transaction which doesn’t look good.
update [1]
val trans = Transaction(trs.payment, Parts(
Person(trs.parts.from.id, "John"),
trs.parts.to)
)
Another is to use copy
update [2]
val stansTrs2 = trs.copy(
parts = trs.parts.copy(
from = trs.parts.from.copy(
name = "John"
)
)
)
And the copy version doesn’t look good either. Even though it’s tolerable now, the bigger the data structure, the uglier the code look like. On a deeply nested immutable data structure, it looks like a triangle instead of a simple call chain from the mutable world.
ohhhh
val stansTrs2 = trs.copy(
parts = trs.parts.copy(
from = trs.parts.from.copy(
person = trs.parts.from.person.copy(
parts = trs.parts.from.person.parts.copy(
from = trs.parts.from.person.parts.from.copy(
person = trs.parts.from.person.parts.from.person.copy(
parts = trs.parts.from.person.parts.from.person.parts.copy(
from = trs.parts.from.person.parts.from.person.parts.from.copy(
person = trs.parts.from.person.parts.from.person.parts.from.person.copy(
parts = trs.parts.from.person.parts.from.person.parts.from.person.parts.copy(
from = trs.parts.from.person.parts.from.person.parts.from.person.parts.from.copy(
name = "jonh"
))))))))))))
Don’t get me wrong, I like parentheses. It feels like a lisp (which I like a lot), but what no one likes is the wall of boilerplate above.
Persistent Data Structures
But talking about lisps, there is another awesome language called Clojure. It’s a lisp running on JVM where every data structure is persistent (don’t confuse with immutable). In Clojure, the same problem can be solved by defining the transaction structure as a persistent map.
create
(def ts {:payment {:currency "AUD"
:amount 15}
:parts {:from {:id 0
:name "Alex"}
:to {:id 1
:name "Ben"}}})
Not as concise as Kotlin’s version, but still pretty good. What is completely different to Kotlin, is the update function
update
(def ts2 (assoc-in ts [:parts :from :name] "John"))
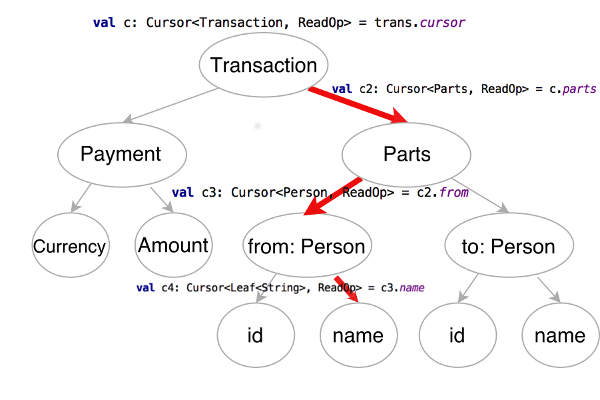
It’s only one line! And it’s exactly what we aimed for. The next picture might be essential for understanding how it works.

Given that each node has a known type - clojure.lang.APersistentMap -
and the universal way of traversing is map.get("key"), it’s possible
to write a function assoc-in which can change a value under a given
"path" and to recreate the data structure node by
node. But Clojure’s internals
are plain java classes that can be used from Kotlin easily just with a
few "convenience" adapters to keep familiar syntax.
create
val tran = pArrayMap(
"payment" to pArrayMap(
"currency" to "AUD",
"amount" to 15
),
"parts" to pArrayMap(
"from" to pArrayMap(
"id" to 0,
"name" to "Alex"
),
"to" to pArrayMap(
"id" to 1,
"name" to "Ben"
)
)
)
Yes, the creation looks rather ugly. It’s untyped, all the key names are represented as strings, but let’s look at the update function.
update
val trans2 = trans.pUpdate(listOf("parts", "from", "name"), "John")
It’s still as concise and beautiful as Clojure’s one.
But is it possible to build a DSL which keeps types from Kotlin types and provides the conciseness of Clojure?
Cursor DSL
It is possible! Using a special DSL, you can define the structure of the "transactional" domain in a following way.
interface Transaction
val <F> Cursor<Transaction, F>.payment by Node<Payment>()
val <F> Cursor<Transaction, F>.parts by Node<Parts>()
interface Payment
val <F> Cursor<Payment, F>.currency by Leaf<String>()
val <F> Cursor<Payment, F>.amount by Leaf<Int>()
interface Parts
val <F> Cursor<Parts, F>.to by Node<Person>()
val <F> Cursor<Parts, F>.from by Node<Person>()
interface Person
val <F> Cursor<Person, F>.id by Leaf<Int>()
val <F> Cursor<Person, F>.name by Leaf<String>()
This looks scary, but it’s just a bit of necessary boilerplate. This code should be read like
interface Transaction val <F> Cursor<Transaction, F>.payment by Node<Payment>() val <F> Cursor<Transaction, F>.parts by Node<Parts>()
interface Payment val <F> Cursor<Payment, F>.currency by Leaf<String>() val <F> Cursor<Payment, F>.amount by Leaf<Int>()
interface Parts val <F> Cursor<Parts, F>.to by Node<Person>() val <F> Cursor<Parts, F>.from by Node<Person>()
interface Person val <F> Cursor<Person, F>.id by Leaf<Int>() val <F> Cursor<Person, F>.name by Leaf<String>()
The creation looks very similar to the untyped version, but it’s completely typed. It references properties defined above.
val trans = domain<Transaction> {
(payment) {
currency.set("AUD")
amount.set(15)
}
(parts) {
(from) {
id.set(0)
name.set("Alex")
}
(to) {
id.set(1)
name.set("Ben")
}
}
}
It’s possible to update the transaction easily. And not just one field, in fact, the code above creates an empty data structure and applies an update function to it.
val trans2 = trans.cursor.parts.from.update {
name.set("John")
}
println(trans.cursor.parts.from.name.value) // "Alex"
println(trans2.cursor.parts.from.name.value) // "John"
or
val trans3 = trans2.cursor.update {
(payment) {
currency.set("USD")
amount.set(12)
}
}
What is really awesome is that the set function can only be called
inside the update block. It’s possible to think about the update
block as an open transaction where a few updates are applied.
Implementation
Read
The easiest way to start implementing it is to imagine that the data
structure is already created and everything we need to do is to read a
value from it. The obvious untyped solution will be to call
trans.get("parts").get("from").get("name"). And this approach works
fine until we need to update it. After the first get call, the
reference to the root transaction is lost and there’ll be no way to run
the update operation.
Instead, it’s possible to focus on the way of traversing the data
structure without loosing the reference to the root. To accomplish this,
it’s possible to implement Focus interface which holds the reference
to the root and accumulates a path inside.
interface Focus<out Op> {
fun narrow(k: String): Focus<Op>
val op: Op
}
The interesting thing that Focus is parametrised over an operation.
That operation can be Read or Write depending on the context. When a
leaf is reached, the typed version will finally perform an action using
that operation.
narrow down the usage
val f = Focus(trans) // {"root" -> Transaction, path -> []}
val f2 = f.narrow("parts") // {"root" -> Transaction, path -> ["parts"]}
val f3 = f2.narrow("from") // {"root" -> Transaction, path -> ["parts", "from"]}
// ...

But even though the focus does its job very well, it’s completely untyped, and strings have to be used to navigate through. The type must be stored somewhere. As everyone knows that any problem can be solved with an additional layer of abstraction! Let’s define a wrapper parametrised over the type of an underlying node.
the missed layer
class Cursor<out T, out Op>(val f: Focus<Op>)
Cursor is parametrised over a node type and the operation is derived
from the focus. And now, the Transaction definition starts making
sense. The narrowing can be delegated to the Node object that knows
the type and uses the name of a property to create a new Cursor with a
new Focus inside.
interface Transaction
val <F> Cursor<Transaction, F>.payment by Node<Payment>()
Here, the payment is an extension property on the Transaction type
which is just a marker interface. It will never be instantiated, instead
by delegating property to Node<Payment>, the conversion
Cursor<Transacton, F> => Cursor<Payment, F> will be made.
how Node is defined
open class Node<out T> {
open operator fun <Op> getValue(ref: Cursor<*, Op>, property: KProperty<*>): Cursor<T, Op> {
return Cursor(ref.f.narrow(property.name))
}
}
Inside Node, a new Cursor is created with the focus narrowing down
using a property name. Using this technique, by just calling extension
properties a focus can narrow down to the last node where the last node
is delegated to Leaf instead of Node.
interface Person
val <F> Cursor<Person, F>.name by Leaf<String>()
Leaf<V> is defined in the same way as Node except for the return value
of getValue.
open class Leaf<out V> {
open operator fun <Op> getValue(ref: Cursor<*, Op>, property: KProperty<*>): Cursor<Leaf<V>, Op> {
return Cursor(ref.f.narrow(property.name))
}
}
Leaf is needed to define an extension property that allows reading a
value from that node. The property has the following signature
val <V, T> Cursor<Leaf<V>, Read<T>>.value: V which says: given the
cursor focused on a leaf and parametrised over a read operation, provide
a value contained by the leaf.
The remaining logic is described below
// the main data structure where T type - is the root type
// in our case, T is Transaction.
// root is just an empty persisntent map
class Domain<out T>(val root: PMap = PHashMap.EMPTY)
// The read operation that focus owns (Op)
interface Read<out M> {
val path: Path // path to the current node (ex. ["payment", "currency"])
val domain: Domain<M> // the reference to the root
}
// the implementation of the focus
class Reader<out T>(val p: Path, val dm: Domain<T>) : Focus<Read<T>> {
// this is how narrowing happens, just extend the path and keep the refernce to the root
override fun narrow(k: String): Focus<Read<T>> = Reader(p.append(k), dm)
override val op: Read<T> = object : Read<T> {
override val domain: Domain<T> = dm
override val path: Path = p
}
}
// take a focus, take a read operation from it and ask for value
// by traversing the root using path
val <V, T> Cursor<Leaf<V>, Read<T>>.value: V
get() = f.op.path.getIn(f.op.domain.root) as V
// this is how cursor get's created, emtpy path and reference to the root
val <T> Domain<T>.cursor: Cursor<T, Read<T>>
get() = Cursor(Reader(Path.EMPTY, this))
Update
So far we can traverse the data structure and read values from it. The next step is to learn how to update it. Problems start when we realise that the underlying data structure is persistent and there is no way to mutate it. To emulate mutation, a special wrapper has to be defined. It reassigns the reference after each mutation.
immutable ⇒ mutable
class Mutable(var m: PMap) {
fun write(p: Path, a: Any?) {
m = p.assocIn(m, a)
}
fun read(p: Path) = p.getIn(m)
}
Then, we’ll need to implement the Write operation which supports
reading and writing under a specific path. At first glance, read
operation is unnecessary, but it’s needed to read the final result after
all modification were applied using an empty path. Another application
of the read() operation is node initialisation. E.g. if you create an
empty domain and decide to write a value to leaf using a cursor, all the
parent nodes need to be initialised first.
Op for Cursor<T, Write>
interface Write {
fun read(): Any?
fun write(a: Any?)
}
And the corresponding cursor
class WriterCursor(val m: Mutable, val path: Path) : Focus<Write> {
// exactly the same narrowing pattern
override fun narrow(k: String): Focus<Write> = WriterCursor(m, path.append(k))
override val op: Write = object : Write {
override fun write(a: Any?) = m.write(path, a)
override fun read(): Any? = m.read(path)
}
}
And at some point in time, we might want to switch from the Read
cursor to the Write cursor. For that, a special function exists.
Cursor<T, Read> ⇒ Cursor<T, Write>
fun <T, M> Cursor<M, Read<T>>.update(update: Cursor<M, Write>.() -> Unit): Domain<T> {
// take a root, make a mutable from it
val m = Mutable(f.op.domain.root)
// create a writer from mutable and apply `update` supplied from outside
// exactly the same pattern as any other DSL has
Cursor<M, Write>(WriterCursor(m, f.op.path)).update()
// read the final value from the root and return a new instance of Domain
return Domain(m.read(Path.EMPTY) as PMap)
}
// to simplify the initialisation
fun <M> domain(f: Cursor<M, Write>.() -> Unit) = Domain<M>().cursor.update(f)
And finally, a set of public typed operation that API consumers use
// for each leaf initial value is null
// for each node initial value is empty persistent map
fun Write.init(k: KClass<*>) {
if (read() == null) {
write(when (k) {
Leaf::class -> null
else -> PArrayMap.EMPTY
})
}
}
operator inline fun <reified T> Cursor<T, Write>.invoke(
updateFn: Cursor<T, Write>.() -> Unit): Unit {
// init the current node (it might be null if we haven't visited it before)
f.op.init(T::class)
updateFn()
}
fun <T> Cursor<Leaf<T>, Write>.set(t: T): Unit {
// just delegate to write
f.op.write(t)
}
The invoke function is responsible for Node initialisation whereas
set sets the Leaf’s value
domain<Transaction> {
(payment) { // <- here invoke is called
currency.set("AUD")
amount.set(15)
}
}
// ↑ is equal to the desugarised version ↓
domain<Transaction> {
payment.invoke({
currency.set("AUD")
amount.set(15)
})
}
And at the end, a Path that does all the work, but in fact, it does nothing except for delegating functionality to functions from Clojure that do all the work on untyped persistent data structures.
import clojure.`core$assoc_in` as assocIn
import clojure.`core$get_in` as getIn
import clojure.lang.*
data class Path(private val v: APersistentVector) {
companion object {
val EMPTY = Path(PersistentVector.EMPTY)
}
fun append(a: String): Path = Path(v.cons(a) as APersistentVector)
fun getIn(model: Any?): Any? = getIn.invokeStatic(model, v)
fun assocIn(m: Any?, a: Any?): Any? = assocIn.invokeStatic(m, v, a)
}
Using these primitives, we built a really powerful type safe DSL to work on immutable data structures. Yes, it has a few downsides. E.g. data classes solution has better performance. And most of the time it’s concise enough, unless you have a really deeply nested tree. In that case, you might also try to use the lenses pattern which comes from the functional world and solves the same problem. But if you already have untyped data structures in your project and have to work with them, Kotlin provides a truly unique set of features that allows you to build a powerful DSL to make your life safer and easier.
It’s very probable that some parts of the solution shown above might still be unclear, in that case, I encourage you to clone the code example in your IDE, run it and try to play with types. It will help a lot and can give you some interesting ideas on how advanced Kotlin features can be used.
Conclusions
-
Kotlin provides many unique features to build DSLs easily
-
DSLs in Kotlin work best as configuration APIs
-
They can be a powerful abstraction over untyped data structures
Warnings
-
Most of the time plain code is better than DSL There is no point in building DSL "just because I can", plain Kotlin code is often much easier to read and understand.
-
Provide a way to extend and bypass your DSL If you publish DSL as a part of your API, it’s always a good idea to give a way to bypass or extend it. Of course, if it’s a Gradle-like DSL then you can cover everything. But in the case of a html DSL, a user might want to introduce some tags that your DSL doesn’t support. Or, he can have an already rendered string which needs to be inserted somewhere.
Links
-
Why you should use DSLs: Building DSL Instead of an IDE Plugin
-
Why you shouldn’t: DSLs in Kotlin: The Good, the Bad and the Ugly
Thanks
-
Kotlin team for creating an awesome language! Please, press a ★ button on the Kotlin’s GitHub repo if you haven’t done it yet.
-
@JetZajac who initially came up with the idea of persistent data structure based DSLs
-
You for reading it
Share this article
Subscribe
I'll be sending an email every time I publish a new post.
Or, subscribe with RSS.