By Sergey Tselovalnikov on 23 July 2020
You don't need no Service Mesh
Hi!
Service meshes have attracted an enormous amount of hype around them. With at least a few talks about service meshes during each tech conference, one can easily be convinced that having a service mesh in their infrastructure is a must. However, hype isn’t a good indicator of whether the new shiny tech is the right solution for your problems. So below, I’ll try to express an anti-hype opinion on service meshes to hopefully make it less confusing when you want to decide whether you may or may not need one.

There’s a lesson here, and I’m not going to be the one to figure it out.
The invention
Let’s take a step back in history and take a look at one of the early articles about introducing Envoy at Lyft.
As it turns out, almost every company with a moderately-sized service oriented architecture is having the same problems that Lyft did prior to the development and deployment of Envoy:
An architecture composed of a variety of languages, each containing a half-baked RPC library, including partial (or zero) implementations of rate limiting, circuit breaking, timeouts, retries, etc.
Differing or partial implementations of stats, logging, and ….
While Envoy is not a service mesh by itself, the outlined problems describe the exact reason why service meshes were invented. They add “rate limiting, circuit breaking, …” and other reliability, observability, and security features to the services by enforcing the communication to go through the service mesh proxies, a data plane. Additionally, they require a separate component, a control plane, to control the configuration.
However, at this point, a lot of people miss the context in which service meshes were introduced. Service meshes are able to solve the problem not because it’s impossible to solve them in any other way. There are many battle-proof RPC libraries that take on the challenges of a separate data plane layer, Finagle, gRPC, Armeria, Servicetalk, to name a few. After all, the very first service mesh - Linkerd 1.0 is powered by Finagle. The RPC libraries will need a component which provides service discovery and configuration management to make it a true mesh. For instance, Zookeeper, or Consul, a component that service meshes call a control plane.
Why introduce a new concept to solve the problems that have been solved before? The service mesh concept wasn’t introduced to address problems that hadn’t been addressed before but rather address them in a way that doesn’t require any modifications to the application code, which is incredibly convenient when it’s hard to introduce an RPC layer into an existing heterogeneous microservice environment.
When you hear service mesh, Istio with Envoy might be the first thing that comes to mind, but it wasn’t the first service mesh to enter the market. Linkerd authors who pioneered the space, described exactly this situation in the "why is the service mesh necessary". Interestingly, in many hype-y articles on the Internet this context is often forgotten, or omitted.
Solving a problem well, even if it’s a problem that a lot of people have, doesn’t magically provide the tech with a lot of hype. There is always a sponsor behind it. I don’t know who the sponsor was here, and I’m going to speculate, but it’s hard to sell an RPC library in the world where open source is a fundamental requirement. There is no clear business model there, that’s why most of the mature RPC libraries were open-sourced by large tech companies for which it’s not a part of the core business model. A library is just code, not a piece of infrastructure. Service meshes are a different story. It’s an isolated non-trivial piece of infrastructure. As a vendor, not only can you provide consultancy around the configuration and deployment, but you can also sell complete hosted solutions around it.
Disillusionments
Now that we’ve established the problems, the solution, and most importantly, the context in which the solution was made, let’s take a look at the alternatives. The most obvious one, in the spirit of KISS, is to use an RPC library for your preferred language. Here is where the context is crucial: if you have a large fleet of services, each written in its own language/ecosystem, and the only language that they share is HTTP then having a single shared RPC library is going to be hard. Perhaps, you’ve got a fabric of deployed and running services, but everyone is afraid of touching them, no one knows how they work, and each redeploy is an adventure. A service mesh is here to help you, because at least you’ll be able to roll out new infrastructure features to the mesh regularly.
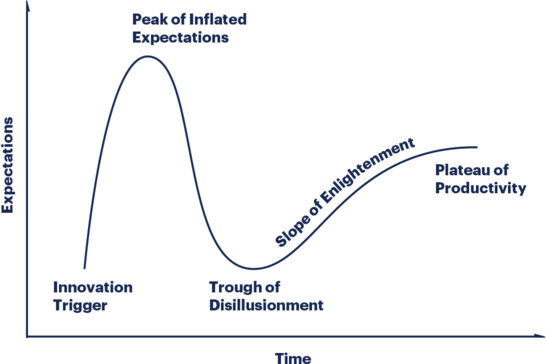
On the other hand, if you have a fleet of healthy services written in a single application stack, then it’s a good idea to think twice before introducing a service mesh. By simply introducing or evolving a shared RPC library, you’ll get the exact same benefits and avoid dealing with the downsides of maintaining service meshes. By studying the service mesh limitations thoroughly, you can avoid finding yourself in the trough of disillusionment.
Different ecosystem
The ecosystem of the service mesh of your choice will likely be different from the ecosystem of your services. Beautiful websites always make you believe that the solution is plug’n'play, always works and never goes down. In reality, sooner or later problems, bugs, quirks in behaviour will reveal themselves, as they always do. At that point, you’ll need to have engineers who work on the service-mesh’s ecosystem which when it’s different from the main app, effectively limits the set of people who can introduce changes or fix problems. This is likely to reintroduce silos, which is against the whole DevOps spirit. Yes, having a DevOps team of engineers who are doing DevOps-y things is against DevOps.
Unnecessary overhead
Not only having a proxy in front of each service adds overhead (often significant, talking about 90pt rather than 99pt in the performance summary doesn’t make software run faster) and consumes resources, but you also requires time (or rather a team of people) to manage them. Yes, it can help to make some of the tasks potentially easier - yay, you can now add canary deployments with a few lines of YAML to simple applications now. However, you still need to manage canary deployments of the proxies themselves which don’t have a proxy in front of them. The problems just get pushed up the stack.
Limiting your architecture to what The Proxy supports.
As you’re reading this paragraph, HTTP/3 is slowly being rolled out to the Internet. It uses UDP as transport. Why use UDP rather than create a completely new protocol you ask? That’s because anything but TCP and UDP is simply “blocked” by the boxes, various proxies on the internet - routers, gateways, etc. This phenomenon got named ossification. So, only TCP or UDP are left is the practical chose, and even UDP is partially blocked by various corporate proxies which slows down the adoption.
Even though your microservice environment is probably much smaller compared to the Internet, you can draw parallels with service meshes. Proxies can ossify your application architecture by limiting how your services talk to each other, and there is not much benefit in having proxies if you can bypass them. Suppose you want to build a reactive application which is using RSocket over pure tcp? Or perhaps a message-driven application using an actor model? Or maybe push the performance boundaries with Aeron? Not going to happen until the box in the middle becomes aware of the protocol.
Do I need one?
What does it all mean for you as an engineer? The answer to whether you need to adopt the service mesh approach comes down to the state of the microservice environment you’re trying to improve. As we have established, compared to an RPC framework, service meshes allow you to:
- Deploy the infra changes more often than deploying your services.
- Introduce infra changes without touching the service code.
The point 1. is important when for whatever reason you can’t redeploy your services very often, e.g. maybe no one remembers how it’s done anymore, or maybe there are other restrictions. The point 2. is important when your stack is heterogeneous, e.g. some services are built in Go, some in Java, some in Haskell, etc. Where are you on the interval from a huge set of heterogeneous services with unknown deployment schedules to a set of homogenous regularly deployed services defines whether a service mesh is the best solution for you.
Conclusion
Service meshes have a lot of hype around them, and way too much in my opinion. However, before committing to a piece of technology, it’s crucial to understand the problems it solves, and the context in which the solution was made. A service mesh is not an ultimate “good practice” but simply one of the patterns to solve a set of issues, and it’s quite a heavy one.
Rather than jumping on board, look carefully - the last thing you want is to find out that you have invested in a solution for a problem that you don’t have. Service meshes are an amazing piece of tech solving a whole lot of problems. Not in every case, it is the best solution.
Thank you to
- You for reading this article.
- Paul Tune for reviewing the article.
References
- https://eng.lyft.com/envoy-7-months-later-41986c2fd443
- https://github.com/linkerd/linkerd/
- https://servicemesh.io/
- https://continuousdelivery.com/2012/10/theres-no-such-thing-as-a-devops-team/
- https://http3-explained.haxx.se/en/why-quic/why-ossification
- https://linkerd.io/2017/04/25/whats-a-service-mesh-and-why-do-i-need-one/#why-is-the-service-mesh-necessary
Discuss on
Subscribe
I'll be sending an email every time I publish a new post.
Or, subscribe with RSS.